
L’intelligence artificielle et les neurosciences cognitives sont étroitement liées. Du fondement des réseaux de neurones artificiels reprenant le calcul réalisé par un neurone organique au mécanisme de récompenses utilisé dans l’apprentissage par renforcement, l’intelligence artificielle et le cerveau humain partagent de nombreux points communs. Et pour cause, le développement des neurosciences à la fin des années 60 hérité de la neuropsychologie et des sciences cognitives et enrichies des évolutions de l’informatique, de la chimie et de la psychologie a permis de grandes avancées dans la compréhension du cerveau et de l’intelligence humaine et animale. L’étude des mécanismes du cerveau a permis de développer des systèmes et des principes fondamentaux dont l’informatique et l’algorithmie en plein essor ont pu profiter pour développer les premières intelligences artificielles. Ces dernières ont été largement améliorés depuis et ont surtout été multipliées et infusées dans toute la société. Selon un rapport publié par l’Organisation Mondiale de la Propriété Intellectuelle (OMPI) en 2019, le nombre de brevets en intelligence artificielle s’est accentué de 28% en moyenne par an entre 2012 et 2017. Cette croissance témoigne d’un intérêt grandissant pour l’intelligence artificielle dans nos sociétés ainsi que de son omniprésence potentielle. L’intelligence artificielle est un outils puissant et complexe qui, en se développant dans de nombreux secteurs, va altérer nos modes de fonctionnement sociétaux. Il semble alors sensé et même essentiel de s’interroger sur son utilisation dans nos sociétés et pour cela, l’étude du rapport entre l’intelligence artificielle et les neurosciences peut nous éclairer.
La première étape passe par la compréhension de la proximité mais surtout des différences persistantes entre cognition humaine et intelligence artificielle.
Les fondements de la cognition artificielle et de la cognition humaine sont assez semblables. Tous deux prennent des informations en entrée : nourris par nos sens pour un cerveau et par des capteurs ou des flots de données pour une intelligence artificielle. Ces informations sont ensuite traitées par des couches de neurones réalisant des micros-calculs successifs jusqu’à produire des résultats en sortie. Le calcul réalisé dans un neurone artificiel est une version simplifié de celui d’un neurone organique découvert dès 1943 par Warren McCulloch et Walter Pitts. Avec l’évolution de la technologie, la quantité de transistors que l’on peut connecter sur un puce électronique se rapproche du nombre de neurones que nous avons dans un cerveau humain, soit environ cent milliards. Si quantitativement les deux se rapprochent, des différences fondamentales subsistent entre les deux. La première importante est l’unilatéralité du flux d’information passant dans le réseau de neurones artificiels. Cette unilatéralité empêche une rétroprojection de chaque couche sur celles d’avant ce qui n’est pas le cas dans un cerveau humain ou l’information est bidirectionnelle et forme des boucles. La principale conséquence de cela est la grande différence de complexité entre cognition humaine et artificielle auquel les mathématiques d’aujourd’hui ne nous permettent pas d’accéder. En résulte une inégalité intrinsèque (pour l’instant) des possibilités des deux cognitions. L’utilisation de l’intelligence artificielle dans la société ne peut donc être similaire à celle de l’intelligence humaine.
La deuxième différence fondamentale est la quantité de données nécessaires. Pour entraîner une intelligence artificielle, une quantité phénoménale de données doit être entrée pour que l’intelligence deviennent plus fiable. Avec une intelligence humaine, une telle quantité n’est pas nécessaire car le cerveau humain fait des inférences plus simplement entre les informations et le « sens commun » nous permet de comprendre bien plus avec bien moins. Chaque détail qu’une intelligence artificielle devra comprendre devra être raffiné à l’aide de grandes quantités de données. Si l’on veut qu’une intelligence artificielle reconnaisse un chien d’un chat, on devra lui injecter des centaines voire des milliers de photos de chats et de chiens différents et si un jour on lui montre une photo de chien d’une espèce différente ou avec un détail particulier, elle ne sera pas nécessairement en mesure de l’identifier comme un chien. Un humain, même jeune pourra en ayant simplement vu quelques chiens, savoir presque tous les reconnaître. Cette différence apporte trois choses dans la compréhension de l’intelligence artificielle dans la société. D’abord la différence de tâches auxquels peuvent être assignés les intelligences artificielles qui vont être bien meilleures pour des actions répétitives par exemples. Elles seront bien meilleures que des humains sur ces tâches précises mais également presque incapables sur d’autres tâches qui pour l’instant doivent rester humaines. Ensuite, les activités pouvant être touchées par l’intelligence artificielle doivent obligatoirement pouvoir produire de grandes quantités de données, ce qui est loin d’être possible dans tous les domaines. On peut ainsi analyser la société et voir quels secteurs peuvent profiter d’une plus grande instauration d’intelligences artificielles et ceux pour lesquels c’est encore trop tôt voire impossible. Enfin, les bases de données nécessaires au développement de telles systèmes requiert dans la majorité des cas une indexation ou une labellisation manuelle, fastidieuse et peu rémunérée qui posent des questions éthiques. Est-ce que cela vaut le coup et à quel prix ? Nous reverrons ces considérations éthiques ultérieurement.
La troisième différence fondamentale est l’incompréhension par l’intelligence artificielle du monde qui l’entoure et l’impossibilité de discuter avec elle pour accéder à cette incompréhension. Hors de sa zone de compréhension acquise par l’injection de données, l’intelligence artificielle est incapable de se repérer et d’agir. Tant que nous n’aurons pas créé d’intelligences artificielles universelles (et nous en sommes encore loin) ou avec du bon sens, elles n’en seront pas capables. En plus de cela, toutes les « conjectures » émises par l’intelligence artificielle ne sont pas accessibles à un individu extérieur, elle agit comme une boîte noire. Pour reprendre l’exemple de la détection du chien et du chat, même si l’intelligence artificielle détecte cent pour cent des chiens, on ne pourra savoir sur quels critères. Et si cette précision n’est qu’à 99,99% on ne pourra savoir pour quelle raison elle s’est trompée ce qui rendra plus compliqué son amélioration et surtout sa communication avec l’Homme de ses défauts. Il y a comme une asymétrie d’information et un « mode de pensée » différent qui empêche une communication réciproque efficace. Dans le monde réel, cela peut avoir de graves implications. Certains pays comme les Etats-Unis ont adopté des systèmes de polices prédictives comme PredPol. Cette intelligence artificielle est censée déterminer l’apparition d’un crime jusqu’à douze heures avant qu’il se produise et donner un zone probable d’arrivée afin que la police puisse renforcer la surveillance dans ces zones. Le modèle de PredPol comme celui de plusieurs de ses concurrents est enrichi de données policières et criminelles ainsi que de nombreux autre facteurs pour ses concurrents (proximité de bars et restaurants, de transports en commun, météo, etc.). Il a développé dans son système de prédiction une logique qui lui est propre et qui est opaque (en plus des critiques de choix des entrées qu’on peut déjà lui faire). Si PredPol fait une erreur, on ne saura pas pourquoi il l’a fait ni quel élément on pourrait modifier pour que ça ne soit plus le cas. C’est un point très important à prendre en compte pour l’utilisation de l’intelligence artificielle dans notre société et qu’il faudra améliorer ou au moins appréhender différemment et communiquer dessus pour intégrer plus l’intelligence artificielle. Nous reviendrons ultérieurement sur les problèmes juridiques que cela pose de surcroît.
La meilleure manière d’intégrer l’intelligence artificielle à nos société est de comprendre nos différences de cognition et de profiter de la complémentarité que cela nous offre. Le roboticien Ken Goldberg de l’Université de Berkeley a développé la notion de « multiplicity » pour illustrer l’idée d’interaction (déjà présente aujourd’hui) entre machines et humains. A l’aide des neurosciences cognitives permettant de comprendre les effets d’une utilisation de l’intelligence artificielle sur le cerveau, on peut en développer des plus performantes et adaptées à cette idée de multiplicité. La complémentarité doit être au cœur de la réflexion pour maximiser le bénéfice de leur utilisation dans la société et éviter les travers que cela peut engendrer. Pour cela, nous pouvons étudier comment maximiser cette « multiplicity » en reprenant un à un les décalage entre intelligence artificielle et humaine.
Le premier de ces décalages est directement reliée à la manière d’apprendre d’une intelligence artificielle et à l’opacité de ses « conclusions » évoqués plus tôt. L’intelligence humaine s’attache au sens des choses et les relient de manière logique entre elles. Notre système de langage par exemple est symbolique : ce sont des signifiants qui symbolisent des signifiés. Les premières intelligences artificielles créées étaient également symboliques. On souhaitait créer un monde symbolique avec des règles bien découpées et tout devait être classé et symbolisé. Le but était de modéliser le raisonnement pour manipuler les symboles. Ce principe permettait aisément une compréhension entre l’intelligence artificielle et l’Homme avec des systèmes clairs et bien classifiés. Cependant, cette vision s’est vite essoufflée à cause de plusieurs problèmes. D’abord, l’ampleur de la tâche pour tout symboliser et classifier en plus de se mettre d’accord sur une symbolisation précise pour chaque élément ce qui est humainement impossible. Ensuite, le système ainsi développé était « monotone » c’est-à-dire qu’il ne fonctionnait que dans un sens. Chaque nouvelle règle ajoutée pour accroître la connaissance ne pouvait outrepasser celles apprises avant et donc annuler des connaissances anciennes erronées. Enfin, l’ordinateur ne comprenait pas lui-même le sens des symboles appris et ne les reliait pas forcément à d’autres représentations du monde dans un sens non-symbolique. Dorénavant, l’intelligence artificielle est dans une conception connexionniste reposant plus sur la complétion et l’abstraction des connaissances où les opérations sont probabilisées. Le raisonnement est découpé en opérations élémentaires et il manque une compréhension globale. Cela engendre un réel problème d’interprétabilité en plus de nécessité une grande quantité d’information comme nous avons pu le voir plus tôt. Dès lors, l’échange entre Homme et machine devient plus complexe et on doit prendre en compte cette différence dès la conception de l’interface pour une bonne utilisation dans la société. Pour aller plus loin, on peut même prendre en compte les répercutions que cela peut avoir. Par exemple en connaissant les erreurs humaines liées à la décision d’inhibition dans le passage du signifiant au signifié (partie jaune sur le schéma) une intelligence artificielle peut laisser une marge d’erreur adaptée à l’Homme pour une meilleure intégration, plus naturelle. De même, en étudiant des mécanismes comme les associations excitatrices, les systèmes de prédictions automatiques peuvent être améliorées en prenant en compte ces spécificités du cerveau humain. Le principe est le même pour les associations sémantiques qui nous font rapprocher plusieurs termes ou nombres en fonction de certaines similitudes.
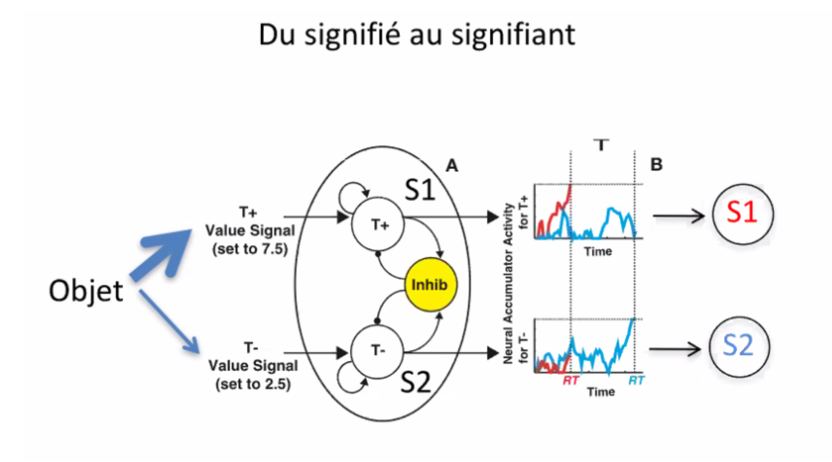
Le second décalage réside dans la fonction optimale des deux cognition qui devrait en résulter des utilisations différenciées. Si le cerveau possède une grande capacité à traiter pleins de petites informations et à les structurer, il ne fera jamais exactement deux fois la même chose. De plus il n’est pas fait pour traiter des données intensément grandes. A l’inverse, une machine est efficace pour maximiser ce qu’il se passe sur une dimension donnée. Elle permet le traitement de données quantitativement grandes et des actions répétées mais ne sera pas efficace pour de la synthèse. En comprenant cette différence, on peut favoriser la «multiplicity» de Ken Goldberg et utiliser l’intelligence artificielle pour compléterle cerveau dans ce qu’il n’aime pas ou ce qu’il ne sait pas faire.
L’utilisation de l’intelligence artificielle dans la société pose de nombreuses questions éthiques et sociétales qui peuvent être en accord ou au contraire en opposition avec nos valeurs. L’usage des neurosciences cognitives permet d’en comprendre les tenants et les aboutissants.
Les systèmes de décisions automatiques par intelligences artificielles sont désormais partout. Ils occupent aussi bien des rôles relativement peu importants (exemple : filtrage de contenu) que des rôles pouvant avoir un impact décisif sur la vie d’un individu (exemple : APB/Parcoursup). Il semble important au regard des neurosciences cognitives d’avoir plus de transparence et d’ouverture sur le fonctionnement de ces mécanismes de décisions. Il semble plus facile à faire accepter et aussi plus éthique d’avoir des explications liées aux décisions prises par des algorithmes plutôt qu’un mur opaque. Malheureusement, comme nous l’avons vu auparavant, les intelligences artificielles connexionnistes peuvent donner des résultats (et prendre des décisions) sans pour autant être capable de les expliquer. Il y a donc, ici encore une incompatibilité partielle de l’utilisation d’intelligences artificielles dans des contextes sociétaux humains. Il faudrait revoir les processus de jugements par intelligences artificielles pour qu’ils soient plus en adéquation avec les mécanismes de décisions du cerveau humain. Nous pouvons aussi nous redemander quelle part des décisions et de l’ingérence dans la société nous voulons leur déléguer (la surveillance et la cybersécurité, les systèmes sanitaires, le filtrage automatisé de contenu, etc). Une question extrinsèque s’impose également à nous : quelle est la part de responsabilité de dommages potentiels causés par une intelligence artificielle et leur considération comme personne juridique morale.
Ultimement nous pouvons nous poser la question externe mais liée de la dissonance cognitive engendrée par l’utilisation d’intelligence artificielle. Lorsque nous prenons connaissance d’une part de la quantité de données et d’autre part de la nécessité de labellisation des données, cela peut entrer en conflit avec nos valeurs et l’utilité offerte par l’utilisation d’intelligence artificielle dans nos sociétés. La collecte des données est déjà très débattue aujourd’hui (et souvent incomplètement comprise par beaucoup) et la labellisation effectuée la plupart du temps par des « mechanical turk workers » (méconnus du grand public) pose de vraies questions sur l’éthique liées à l’utilisation d’intelligence artificielle dans nos sociétés. On peut légitimement se poser la question du coût social d’une telle entreprise. La méconnaissance d’une majeure partie de la population n’aide pas et la compréhension de ces enjeux par les acteurs de la société devrait être une priorité pour éviter de futurs dissonances cognitives.
Comme nous avons pu le voir, les neurosciences et l’intelligences artificielles ont une histoire commune. Si dans leurs débuts, les neurosciences ont principalement nourri les recherches en intelligences artificielles cela fonctionne aujourd’hui dans les deux sens puisque les recherches de l’un font avancer l’autre. D’après Matthew Botvinick, directeur des recherches en neurosciences chez Deepmind: les neurosciences servent de guide pour l’intelligence artificielle et donnent des méthodes pour valider les idées qu’elles développent. De plus, le développement concomitant des deux disciplines permet de faire émerger une plus grande variété d’intuitions, de points de vue et d’associations. Le lien entre les deux devrait donc perdurer et la prise en compte des limites et des besoins de la cognition humaine pour la création et l’utilisation d’intelligence artificielle et à portée de main. Leur utilisation potentielle dans divers champs comme l’apprentissage scolaire semble ainsi prometteuse.
Rédigé le 11 mai 2020
Sources :
Les neurosciences - Fédération pour la Recherche sur le Cerveau (FRC) (2020). Available at: https://www.frcneurodon.org/comprendre-le-cerveau/a-la-decouverte-du-cerveau/les-neurosciences/
WIPO, Technology trends 2019, Artificial Intelligence (2019). World Intellectual Property Organization. Available at: https://www.wipo.int/edocs/pubdocs/en/wipo_pub_1055.pdf
McCulloch, W. and Pitts, W. (1943) "A logical calculus of the ideas immanent in nervous activity", The Bulletin of Mathematical Biophysics, 5(4), pp. 115-133. doi: 10.1007/bf02478259.
Knight, W. (2020) Watson's Creator Wants to Teach AI a New Trick: Common Sense, Wired. Available at: https://www.wired.com/story/watsons-creator-teach-ai-new-trick-common-sense/
Pavlus, J. (2020) Common Sense Comes to Computers, Quanta Magazine. Available at: https://www.quantamagazine.org/common-sense-comes-to-computers-20200430/
Heffner, J. (2017) Managing Police Patrols with HunchLab: Humility in ML-based Systems, ScholarlyCommons. Available at: https://repository.upenn.edu/admindata_conferences_presentations_2017/2/
Goldberg, K. (2015) Editorial Multiplicity Has More Potential Than Singularity, Ieeexplore.ieee.org. Available at: https://ieeexplore.ieee.org/abstract/document/7057690
Nicholson, C. (2018) Symbolic Reasoning (Symbolic AI) and Machine Learning, Pathmind. Available at: https://pathmind.com/wiki/symbolic-reasoning
Valkenburg, J. (2011) Attention, Reflection and Distraction: The Impact of Technology on Learning, Areyouthinkingnow.com. Available at: https://areyouthinkingnow.com/pilot/wp-content/uploads/2014/09/Attention-Reflection-and-Distraction-Valkenburg.pdf
Graveleau, S. (2016) APB : révélation du code source qui affecte les bacheliers à l’université. Available at: https://www.lemonde.fr/campus/article/2016/10/18/apb-revelation-du-code-source-qui-affecte-les-bacheliers-a-l-universite_5015778_4401467.html
Semuels, A. (2018) The Internet Is Enabling a New Kind of Poorly Paid Hell, The Atlantic. Available at: https://www.theatlantic.com/business/archive/2018/01/amazon-mechanical-turk/551192/
Bentley, J. (2017) Challenges with Amazon Mechanical Turk research in accounting Available at: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2924876
Liu, B. & Sundar, S. (2018) Microworkers as research participants : Does underpaying Turkers lead to cognitive dissonance ? Available at: https://www.sciencedirect.com/science/article/pii/S0747563218302942
Botvinik, M. (2018) Neuroscience and AI. Available at: https://www.youtube.com/watch?v=uv4Hh3wDH14&list=WL&index=3&t=0s Artificial intelligence with human values for sustainable development (2020). Available at: https://en.unesco.org/artificial-intelligence